, 36 min read
Direct st-connectivity with few paths is in quantum logspace
Authors: Roman Edenhofer and Simon Apers
Université Paris Cité, CNRS, IRIF, Paris, France
- Abstract
- 1. Introduction and summary
- 2. Space-bounded computation
- 3. Fewness language in $\mathsf{BQL}$
- 4. Counting few paths in quantum logspace
- Acknowledgements
- References
- Appendix: Effective pseudoinversion in quantum logspace
Abstract
We present a $\mathsf{BQSPACE}(O(\log n))$-procedure to count $st$-paths on directed graphs for which we are promised that there are at most polynomially many paths starting in $s$ and polynomially many paths ending in $t$. For comparison, the best known classical upper bound in this case just to decide $st$-connectivity is $\mathsf{DSPACE}(O(\log^2 n/ \log \log n))$. The result establishes a new relationship between $\mathsf{BQL}$ and unambiguity and fewness subclasses of $\mathsf{NL}$. Further, some preprocessing in our approach also allows us to verify whether there are at most polynomially many paths between any two nodes in $\mathsf{BQSPACE}(O(\log n))$. This yields the first natural candidate for a language problem separating $\mathsf{BQL}$ from $\mathsf{L}$ and $\mathsf{BPL}$. Until now, all candidates separating these classes were promise problems.
1. Introduction and summary
Graph connectivity is a central problem in computational complexity theory, and it is of particular importance in the space-bounded setting. Given a graph $G$ and two vertices $s$ and $t$, the task is to decide whether there is a path from $s$ to $t$. For undirected graphs the problem is denoted as $\mathrm{USTCON}$. Aleliunas, Karp, Lipton, Lovász and Rackoff [AKL+79] showed that doing a random walk for a polynomial number of steps can solve it in randomized logspace, $\mathsf{RL}$. After a long line of work, Reingold [Rei05] was able to derandomize the result and showed that the problem is already contained in deterministic logspace, $\def\L{\mathsf{L}}\L$, and is in fact complete for that class. In the directed graph setting the problem is denoted as $\mathrm{STCON}$, and it is complete for non-deterministic logspace, $\mathsf{NL}$. The best known deterministic algorithm for $\mathrm{STCON}$ in terms of space complexity is due to Savitch [Sav70] and runs in space $O(\log^2 n)$. We have the following well-known inclusions
where $\mathsf{DET}$, introduced by Cook [Coo85], is the class of languages that are $\mathsf{NC}^1$ Turing reducible to the computation of the determinant of an integer matrix and $\mathsf{L}^2$ is the class of languages decidable in deterministic space $O(\log^2 n)$. We refer to [AB06] for further details on reductions and basic complexity classes.
The most studied quantum space-bounded complexity class is bounded error quantum logspace, denoted $\mathsf{BQL}$. This is the class of languages decided in $\mathsf{BQSPACE}(O(\log n))$, i.e., decided by a quantum Turing machine with error $1/3$ running in space $O(\log n)$ and time $2^{O(\log n)}$. The quantum Turing machine has unrestricted access to the input on a classical input tape and can write on a uni-directional output tape which does not count towards the space complexity. The class $\mathsf{BQL}$ lies in between $\mathsf{RL}$ and $\mathsf{DET}$. In fact, it was recently shown by Fefferman and Remscrim [FR21] that certain restricted versions of the standard $\mathsf{DET}$-complete matrix problems are complete for $\mathsf{prBQL}$, where $\mathsf{prBQL}$ is the promise version of $\mathsf{BQL}$, i.e. the class of promise problems decided in $\mathsf{BQSPACE}(O(\log n))$. This extended the earlier work of Ta-Shma [Ta-13], who showed how to invert well-conditioned matrices in $\mathsf{BQSPACE}(O(\log n))$ building on the original idea of Harrow, Hassidim and Lloyd [HHL09]. We restate two of Ta-Shma's main results:
- (Compare Theorem 5.2 in [Ta-13]) Given a matrix $M \in \mathbb{C}^{n \times n}$ with $|M|_2 \leq \mathop{\rm poly}(n)$, we can output all of its singular values and their respective multiplicities up to $1/\mathop{\rm poly}(n)$ additive accuracy in $\mathsf{BQSPACE}(O(\log n))$. In particular, we can determine $\dim(\ker(M))$ if all non-zero singular values have inverse polynomial distance from zero.
- (Compare Theorem 1.1 in [Ta-13]) Given two indices $s,t\in [n]$ and a matrix $M\in\mathbb{C}^{n\times n}$ which is poly-conditioned, by this we mean that its singular values satisfy \begin{align*} \mathop{\rm poly}(n)\geq \sigma_1(M) \geq \cdots \geq \sigma_n(M) \geq 1/\mathop{\rm poly}(n), \end{align*} we can estimate $M^{-1}(s,t)$ up to $1/\mathop{\rm poly}(n)$ additive accuracy in $\mathsf{BQSPACE}(O(\log n))$.
The first result above directly implies a $\mathsf{BQL}$-procedure for deciding $\mathrm{USTCON}$ (alternatively, this follows from the containment $\mathsf{RL}\subseteq \mathsf{BQL}$). To see this, note that (i) $\mathrm{USTCON}$ can be reduced to counting the number of connected components, (ii) the dimension of the kernel of the random walk Laplacian $I-P$ is equal to the number of connected components, and (iii) for undirected graphs the spectral gap of $I-P$, that is its smallest non-zero eigenvalue, is inverse polynomially bounded from zero. Here $I$ is the identity and $P$ is the transition matrix of a random walk. This ties to the fact that a random walk on an undirected graph takes polynomial time to traverse the graph (see, e.g., Chapter 12 in [LPW08]). Unfortunately, for directed graphs the situation is more complicated. Importantly, the smallest non-zero singular value of the random walk Laplacian can be inverse exponentially small, and similarly the time it takes a random walk to find connected nodes can be exponential. Hence, it is not obvious how Ta-Shma's results should be of any help in this setting.
Counting few paths
Somewhat surprisingly, we show that by analyzing a different matrix which we call the counting Laplacian $L = I-A$ we can use Ta-Shma's second result to solve instances of $\mathrm{STCON}$ in $\mathsf{BQSPACE}(O(\log n))$ that seem hard classically. Here $A$ denotes the adjacency matrix of a graph. While the random walk Laplacian is spectrally well-behaved if a random walk is efficient, we find that the counting Laplacian is spectrally well-behaved if the underlying graph is acyclic and contains only few paths. We remark that the number of paths in a graph can be totally unrelated to the success probability of a random walk finding specific nodes. Even if there exist very few paths, it can happen that a random walk has an extreme bias to only pick paths we are not interested in. Consider for instance the following graph:
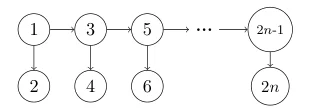
The number of paths between any two nodes is at most one. Nonetheless, a random walk starting at node $1$ only has probability $1/2^{n-1}$ to reach node $2n$.
Remark: There does exist a folklore algorithm running in $\mathsf{DSPACE}(O(\log n))$ for solving $\mathrm{STCON}$ on this graph, and directed trees more generally, as mentioned in, e.g., [kannan2008stcon]. The algorithm builds on a divide-and-conquer strategy that is specifically tailored to these graphs.
Given a directed graph $G=(V,E)$ with nodes $i,j\in V$ let us denote by $N(i,j)$ the number of paths from $i$ to $j$. By a path from $i$ to $j$ we mean a sequence of edges $(e_1,\ldots,e_k)$ which joins a sequence of nodes $(v_0,\ldots,v_k)$ such that $e_i = (v_{i-1},v_i)$ for all $i\in [k]$.
Remark: Some authors call this a walk and disallow a path to visit any vertex more than once. We follow [AL98,kannan2008stcon] in our definition. By convention we also count the empty sequence as a path from any node to itself such that $N(i,i)\geq 1$ for all $i\in V$.
As our first result, and as a primer for the rest of the paper, we show that we can count the number of $st$-paths on directed graphs for which there are at most polynomially many paths between any two nodes in $\mathsf{BQSPACE}(O(\log n))$. In particular, this allows to decide $\mathrm{STCON}$ on such graphs.
Theorem 1.1. Fix a polynomial $p:\mathbb{N} \rightarrow \mathbb{N}$. Let $G$ be a directed graph with $|V(G)|=n$ nodes such that
- $\forall i,j \in V(G): N(i,j)\leq p(n)$.
There is an algorithm running in $\mathsf{BQSPACE}(O(\log n))$ that, given access to the adjacency matrix $A$ of $G$ and $s,t\in V(G)$, returns the number of paths from $s$ to $t$.
Proof: Note that $A^k(i,j)$ is equal to the number of paths of length $k$ from node $i$ to node $j$. Since that number is finite for all pairs of nodes by assumption, we find that the graph is acyclic. In other words, $A$ is nilpotent, i.e., $A^{n}=0$. As a consequence we obtain that the inverse of the counting Laplacian exists and is equal to
Clearly, its entries simply count the total number of paths from $i$ to $j$, i.e. $L^{-1}(i,j) = N(i,j)$. By assumption, we thus have
Now observe that the $\max$-norm of a matrix can be used to bound its spectral norm. More precisely, we have that
Using also that $| L |_{\max} = 1$, we find bounds for the largest and smallest singular value of $L$,
Thus, the counting Laplacian is poly-conditioned and we can apply Ta-Shma's matrix inversion algorithm, the second restated result above, to approximate entry $L^{-1}(s,t) = N(s,t)$ up to additive error $1/3$ in $\mathsf{BQSPACE}(O(\log n))$. Rounding to the closest integer gives the number of paths from $s$ to $t$. ☐
The proof of theorem 1.1 uses a reduction of summing matrix powers to matrix inversion. The idea for this is well-known, and appeared in this context in early work by Cook, and more recently in for instance FR21. Though, to the best of our knowledge, no study of the implications to $\mathrm{STCON}$ has been made yet.
In section 3 we push the algorithmic idea of theorem 1.1 further by doing a more fine-grained analysis of the counting Laplacian's singular values and singular vectors. We show that we can already count $st$-paths in $\mathsf{BQSPACE}(O(\log n))$ on directed graphs for which only the number of paths starting from $s$ and the number of paths ending in $t$ are polynomially bounded. We state the formal result here.
Theorem 1.2. Fix a polynomial $p: \mathbb{N} \rightarrow \mathbb{N}$. Let $G$ be a directed graph with $|V(G)|=n$ nodes such that
- $\forall j \in V(G) : N(s,j) \leq p(n)$ and $N(j,t) \leq p(n)$.
There is an algorithm running in $\mathsf{BQSPACE}(O(\log n))$ that, given access to the adjacency matrix $A$ of $G$ and $s,t\in V(G)$, returns the number of paths from $s$ to $t$.
Classically (deterministically or randomly), the best known space bound just to decide $\mathrm{STCON}$ on graphs promised to satisfy a polynomial bound on the number of paths between any two nodes as in theorem 1.1 or only on the number of paths starting from $s$ and on the number of paths ending in $t$ as in theorem 1.2 is $\mathsf{DSPACE}(O(\log^2(n)/\log\log(n)))$ [AL98,GSTV11]. Alternatively, as noticed in [Lan97,BJLR91] we can also solve such $\mathrm{STCON}$ instances simulatenously in deterministic polynomial time and space $O(\log^2 n)$. We elaborate on these bounds in the next section.
Unambiguity, Fewness and a language in $\mathsf{BQL}$ (maybe) not in $\mathsf{BPL}$
Previous works studied restrictions on the path count in connection to "unambiguity" of configuration graphs of space-bounded Turing machines. The notion of unambiguity was introduced to interpolate between determinism and non-determinism, and gives rise to complexity classes between $\L$ and $\mathsf{NL}$. We formally introduce these classes in section 2. As a direct consequence of theorem 1.1 we obtain:
Corollary 1.3. $\mathsf{StrongFewL} \subseteq \mathsf{BQL}$
Where $\mathsf{StrongFewL}$ denotes the class of languages which are decidable by an $\mathsf{NL}$-Turing machine whose configuration graphs for all inputs are strongly-few, that is graphs for which there are at most polynomially many paths between any two nodes. Since $\mathsf{StrongFewL}$ is not known to lie in $\mathsf{BPL}$, this already implies the existence of a language in $\mathsf{BQL}$ not known to lie in $\mathsf{BPL}$. However, we can obtain an explicit language by doing some preprocessing in the algorithm of theorem 1.1: we can actually check in $\mathsf{BQSPACE}(O(\log n))$ whether a given graph is strongly-few. Unfortunately, we see no way to do the same for the weaker promise of theorem 1.2.
We obtain the subsequent language containment (notably, the containment of this language in $\mathsf{StrongFewL}$ is not known).
Theorem 1.4. The language \begin{align*} \mathrm{STCON}_{\mathrm{sf}} = { \langle G,s,t,1^k\rangle \text{ }|\text{ }\forall i,j\in V(G): N(i,j)\leq k \text{ and } N(s,t) \geq 1 } \end{align*} is contained in $\mathsf{BQL}$.
These seem to be the first examples of languages in $\mathsf{BQL}$ not known to lie in $\L$ or $\mathsf{BPL}$. As far as we are aware, before this work only promise problems were known that lie in $\mathsf{prBQL}$ but which are potentially not contained in $\mathsf{prBPL}$ [Ta-13,FL18,FR21,GLW23].
We now summarize briefly what is known classically. A language similar to $\mathrm{STCON}_{\mathrm{sf}}$, namely
has been studied before. It was first introduced by Lange [Lan97] who showed that it is complete for $\mathsf{ReachUL}$, which is the class of languages decidable by an $\mathsf{NL}$-Turing machine whose configuration graphs for all inputs are reach-unambiguous, meaning that there is a unique computation path from the start configuration to any reachable configuration.
Remark: Note that the $\mathsf{ReachUL}$-hardness of $\mathrm{STCON}_{\mathrm{ru}}$ is trivial but the completeness is not. This is because the uniqueness in the definition of the complexity class is used as a restriction on the machine, while it is used as an acceptance criterion in the definition of the language.
Further, it was noticed in [Lan97, BJLR91] that $\mathsf{ReachUL}$ is contained in $\mathsf{SC}^2$, which is the class of languages decidable simulatenously in deterministic polynomial time and space $O(\log n)$. Additionally, Allender and Lange [AL98] found that $\mathrm{STCON}$ on graphs promised to be reach-unambiguous is solvable in deterministic space $O(\log^2(n)/ \log\log(n))$ implying
In particular, these results put $\mathrm{STCON}_{\mathrm{ru}}$ in $\mathsf{SC}^2$ and in $\mathsf{DSPACE}(O(\log^2(n)/ \log\log(n)))$. Also, more recently Garvin, Stolee, Tewari and Vinodchandran [GSTV11] proved that $\mathsf{ReachUL}$ is equal to $\mathsf{ReachFewL}$, where $\mathsf{ReachFewL}$ is the class of languages decidable by an $\mathsf{NL}$-Turing machine whose configuration graphs for all inputs are reach-few, i.e., they have at most polynomially many computation paths from its start configuration to any reachable configuration. We thus have \begin{align*} \mathsf{StrongFewL} \subseteq \mathsf{ReachFewL} = \mathsf{ReachUL} \subseteq \mathsf{SC}^2, \quad \mathsf{DSPACE}(O(\log^2(n)/ \log \log(n))). \end{align*} Notably, while [GSTV11] implies a procedure to solve $\mathrm{STCON}$ on graphs promised to be reach-few in $\mathsf{DSPACE}(O(\log^2(n) / \log \log(n)))$ (in particular, this includes the graphs from theorem 1.1 and 1.2), this does not allow to verify whether a general graph satisfies this promise. Indeed, none of the upper bounds for $\mathrm{STCON}_{\mathrm{ru}}$ directly carry over to $\mathrm{STCON}_{\mathrm{sf}}$, for which the best known classical upper bound to date seems to be $\mathsf{DET}$.
Conclusion and open questions
Summarizing, we show that in quantum logspace we can count $st$-paths on graphs for which even solving $st$-connectivity is not known to be possible in classical (deterministic or randomized) logspace. Further, we obtain the first (non-promise) language in $\mathsf{BQL}$ not known to lie in $\mathsf{BPL}$. Our work also yields a number of open questions.
An obvious first question is whether $\mathrm{STCON}_{\mathrm{sf}}$ really separates $\mathsf{BQL}$ and $\mathsf{BPL}$. A first step towards answering this might be tackling the related question, whether we can carry over some of the known upper bounds for $\mathrm{STCON}_{\mathrm{ru}}$ to $\mathrm{STCON}_{\mathrm{sf}}$. That is, is $\mathrm{STCON}_{\mathrm{sf}}$ also contained in $\mathsf{SC}^2$ or in $\mathsf{DSPACE}(O(\log^2(n)/\log\log(n)))$? Note that the known $\mathsf{prBQL}$-complete promise problems are not known to satisfy these upper bounds [Ta-13,FL18,FR21,GLW23].
Further, we wonder whether it is possible to improve the $O(\log^2(n)/ \log \log(n))$ space bound by Allender and Lange. In fact, Allender recently asked this in an article [All23] in which he reflects on some open problems he encountered throughout his career. Allender suspects that for the restricted case of strongly-unambiguous graphs, also called mangroves, for which the number of paths between any two nodes is bounded by one, there should exist an algorithm deciding $\mathrm{STCON}$ running in deterministic space $O(\log n)$. He even offers a $1000 reward for any improvement of their space bound, already for this restricted case. A dequantization of our results would thus yield some good pocket money.
Remark: Even if the dequantization were randomized, i.e. in $\mathsf{BPSPACE}(O(\log n))$, it would still imply a $\mathsf{DSPACE}(O(\log^{3/2} n))$ bound by the inclusion $\mathsf{BPSPACE}(O(\log n)) \subseteq \mathsf{DSPACE}(O(\log^{3/2} n))$ due to Saks and Zhou [SZ99].
Another natural question is whether in $\mathsf{BQSPACE}(O(\log n))$ we can solve $\mathrm{STCON}$ on graphs promised to be reach-few, where only the number of paths from $s$ is polynomially bounded. This relaxes our promise in theorem 1.2. Unfortunately, our current approach of using an effective pseudoinverse seems to require our stronger promise. More generally, we feel that a better understanding of the singular values and vectors of directed graph matrices will yield further insights into the utility of quantum space-bounded computation for solving problems on directed graphs.
Finally, the link between poly-conditionedness and bounds on the path count raises the question of whether some variation of $\mathrm{STCON}$ could be proven complete for $\mathsf{BQL}$.
2. Space-bounded computation
In 2.1 we introduce the Turing machine model of space-bounded computation and define the most important appearing language classes. We mainly follow the definitions from Ta-Shma [Ta-13] and refer to Section 2.2 in [FR21] for a discussion on the equivalence of the quantum Turing machine model and the quantum circuit model. In Complete (promise) problems we mention some complete problems of promise versions of the defined complexity classes.
2.1 Turing machines
A deterministic space-bounded Turing machine (DTM) acts according to a transition function $\delta$ on three semi-infinite tapes: A read-only tape where the input is stored, a read-and-write work tape and a uni-directional write-only tape for the output. The TMs computation time is defined as the number of transition steps it performs on an input, and its computation space is the number of used cells on the work tape, i.e. we do not count the number of cells on the input or output tape towards its computation space. DTMs with space-bound $s(n)$ for inputs of length $n$ give rise to $\mathsf{DSPACE}(s(n))$. We define $\L$ as the class of languages decided in $\mathsf{DSPACE}(O(\log n))$ and $\L^2$ as the class of languages decided in $\mathsf{DSPACE}(O(\log^2 n))$.
A non-deterministic Turing machine (NTM) is similar to a DTM except that it has two transition functions $\delta_0$ and $\delta_1$. At each step in time the machine non-deterministically chooses to apply either one of the two. It is said to accept an input if there is a sequence of these choices so that it reaches an accepting configuration and it is said to reject the input if there is no such sequence of choices. We obtain $\mathsf{NSPACE}(s(n))$. Further, $\mathsf{NL}$ is the class of languages decided in $\mathsf{NSPACE}(O(\log n))$.
A probabilistic space-bounded Turing machine (PTM) is again similar to a DTM but with the additional ability to toss random coins. This can be conveniently formulated by a fourth tape that is uni-directional, read-only and initialized with uniformly random bits at the start of the computation. It does not count towards the space. A language is said to be decided in $\mathsf{BPSPACE}_{a,b}(s(n))$ if there is a PTM running in space $s(n)$ and time $2^{O(s(n))}$ deciding it with completeness error $a\in[0,1]$ and soundness error $b\in[0,1]$, that is every input in the language is accepted with probability at least $a$ and every input not in the language is accepted with probability at most $b$.
Remark: The time bound does not follow from the space-bound and is equivalent to demanding that the TM absolutely halts for all possible assignments of the random coins tape.
Also, we write $\mathsf{BPSPACE}(s(n))$ for $\mathsf{BPSPACE}_{\frac{1}{3},\frac{2}{3}}(s(n))$ and $\mathsf{RSPACE}(s(n))$ for $\mathsf{BPSPACE}_{\frac{1}{2},0}(s(n))$. Further, $\mathsf{BPL}$ is the class of languages decided in $\mathsf{BPSPACE}(O(\log n))$ and $\mathsf{RL}$ is the class of languages decided in $\mathsf{RSPACE}(O(\log n))$.
A quantum space-bounded Turing machine (QTM) is a DTM with a fourth tape for quantum operations instead of a random coins tape. The transition function $\delta$ is still classically described. The tape cells of the quantum tape are qubits and initialized in state $\ket{0}$ at the start of the computation. There are two tape heads moving in both directions on the quantum tape. At each step during the computation, the machine can either perform a measurement to a projection in the standard basis or apply a gate from some universal gate set, say ${\mathrm{HAD},\mathrm{T},\mathrm{CNOT}}$, to the qubits below its tape heads. The used cells on the quantum tape count towards the computation space. As before, we say a language is decided in $\mathsf{BQSPACE}_{a,b}(s(n))$ if there is a QTM running in space $s(n)$ and time $2^{O(s(n))}$ deciding it with completeness error $a$ and soundness error $b$. Also, we mean $\mathsf{BQSPACE}_{\frac{2}{3},\frac{1}{3}}(s(n))$ by $\mathsf{BQSPACE}(s(n))$ if not mentioned otherwise. Finally, $\mathsf{BQL}$ is the class of languages decided in $\mathsf{BQSPACE}(O(\log n))$. The particular choice of the universal gate set does not affect the resulting complexity class due to the space-efficient version of the Solovay-Kitaev theorem of van Melkebeek and Watson [MW10]. The same applies to disallowing intermediate measurements, thanks to the space-efficient "deferred measurement principle" proven by Fefferman and Remscrim [FR21] building on the earlier work of Fefferman and Lin [FL18] (see also [GRZ21,GR21] for an alternative time- and space-efficient version of this principle). Also, the chosen success probability of $2/3$ can be amplified by sequentially repeating computations.
2.2 Complete (promise) problems
In this work we only consider language classes. In particular, we present the first candidate to distinguish $\mathsf{BQL}$ and $\mathsf{BPL}$. Note that candidates for distinguishing the promise versions of these classes, $\mathsf{prBQL}$ and $\mathsf{prBPL}$, are well-known. As mentioned in the introduction, Fefferman and Remscrim [FR21] showed that well-conditioned promise versions of all the standard $\mathsf{DET}$-complete matrix problems are complete for $\mathsf{prBQL}$. Let us highlight that matrix powering is one of these problems. Restricted to stochastic matrices it is easily seen to be complete for $\mathsf{prBPL}$, and restricted to matrices for which the largest singular values of its powers grow at most polynomially, it is complete for $\mathsf{prBQL}$. Indeed, this seems to indicate that powering the adjacency matrix of a graph, to which our approach in theorem 1.1 essentially boils down to, rather than powering the corresponding random walk matrix, truly exploits a quantum advantage. A similar distinction of $\mathsf{prBQL}$ and $\mathsf{prBPL}$ is expected from the approximation of the spectral gap of matrices. Doron, Sarid and Ta-Shma [DST17] showed that a promise decision version of this problem is $\mathsf{prBPL}$-complete for stochastic matrices while it is $\mathsf{prBQL}$-complete for general hermitian matrices. More recently, Le Gall, Liu and Wang [GLW23] presented another group of $\mathsf{prBQL}$-complete problems based on state testing.
3. Fewness language in $\mathsf{BQL}$
In section 3.1 we introduce the notions of unambiguity and fewness in space-bounded computation. In section 3.2 we prove theorem 1.4 presenting a language in $\mathsf{BQL}$ not known to lie in $\mathsf{BPL}$.
3.1 Unambiguity and fewness
The computation of a Turing machine can be viewed as a directed graph on configurations, and certain restrictions on the Turing machine translate to natural restrictions on the corresponding configuration graph. The notions of "unambiguity" and "fewness" of a Turing machine relate to the following graph-theoretic notions.
Definition 3.1. Let $G=(V,E)$ be a directed graph and let $k$ be an integer. Then $G$ is called
- $k$-unambiguous with respect to nodes $s,t\in V$ if $N(s,t) \leq k$,
- $k$-reach-unambiguous with respect to node $s\in V$ if for all $j \in V,$ $N(s,j) \leq k$,
- $k$-strongly unambiguous if for all $i,j \in V,$ $N(i,j) \leq k$.
In the case of $k=1$, we simply say $G$ is unambiguous, reach-unambiguous or strongly unambiguous, respectively. Furthermore, a family of directed graphs ${G_x}_{x\in X}$ is called few-unambiguous with respect to nodes $s_x, t_x \in V(G_x)$, reach-few with respect to nodes $s_x \in V(G_x)$ or strongly-few if there exists a polynomial $p:\mathbb{N} \rightarrow \mathbb{N}$ such that each of the graphs $G_x$ from the family with $|V(G_x)|=n$ nodes is $p(n)$-unambiguous with respect to $s_x$ and $t_x$, $p(n)$-reach-unambiguous with respect to $s_x$ or $p(n)$-strongly unambiguous, respectively.
Consider the following examples of the above definition due to Lange [Lan97]:
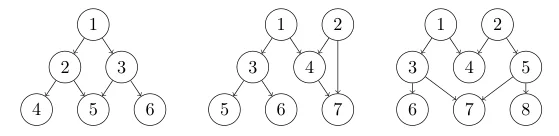
The left graph is unambiguous with respect to nodes $1$ and $6$ but not reach-unambiguous with respect to node $1$, the middle one is reach-unambiguous with respect to node $1$ but not strongly unambiguous and the right one is strongly unambiguous.
These notions of unambiguity and fewness naturally give rise to six complexity classes between $\L$ and $\mathsf{NL}$. We follow the original paper of Buntrock, Jenner, Lange and Rossmanith [BJLR91] and define
- strongly-unambiguous logspace, $\mathsf{StrongUL}$,
- strongly-few logspace, $\mathsf{StrongFewL}$,
- reach-unambiguous logspace, $\mathsf{ReachUL}$,
- reach-few logspace, $\mathsf{ReachFewL}$,
- unambiguous logspace, $\mathsf{UL}$, and
- few logspace, $\mathsf{FewL}$
as the classes of languages that are decidable by an $\mathsf{NL}$-Turing machine $M$ with unique accepting configuration whose family of configuration graphs for inputs $x\in\Sigma^*$, $\{G_{M,x}\}_{x\in\Sigma^*}$, satisfies the corresponding unambiguity or fewness restriction with respect to its starting and its accepting configuration.
Recall that theorem 1.1 implies the inclusion:
Corollary 1.3. $\mathsf{StrongFewL} \subseteq \mathsf{BQL}$
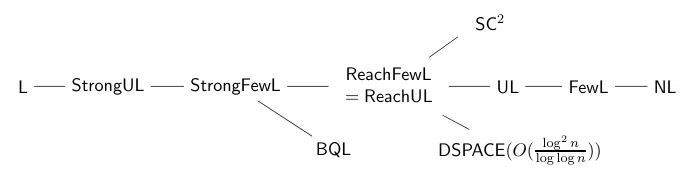
Putting this together with the trivial containments and the previously mentioned results in [BJLR91,Lan97,AL98,GSTV11], we obtain the following inclusion diagram to be read from left to right:
3.2 Proof of theorem 1.4
Observe that theorem 1.1 only shows that we can decide $st$-connectivity on directed graphs that are promised to be strongly-few. We now show that we can also check whether this promise holds in $\mathsf{BQSPACE}(O(\log n))$, i.e. we obtain a language containment. We restate the result mentioned in the introduction:
Theorem 1.4. The language \begin{align*} \mathrm{STCON}_{\mathrm{sf}} = \{ \langle G,s,t,1^k\rangle \text{ }|\text{ }\forall i,j\in V(G): N(i,j)\leq k \text{ and } N(s,t) \geq 1 \} \end{align*} is contained in $\mathsf{BQL}$.
The idea for proving the above theorem is to use Ta-Shma's spectrum approximation procedure to estimate the smallest singular value of the counting Laplacian $L$. In case the smallest singular value is below some threshold, this gives us a lower bound for $|L^{-1}|_{\max}$, the maximum number of paths, so that we can correctly reject graphs with too many paths. In case it is higher than the threshold, we know that $L$ is poly-conditioned and we can proceed as in theorem 1.1 to compute the number of paths between any pair of nodes exactly. Note that for this approach to work, the graph needs to be acyclic so that the counting Laplacian is invertible. We ensure this by first mapping the input graph to a layered graph that is guaranteed to be acyclic, similar as in [GSTV11]. We make the following definition.
Definition 3.2. Let $G=(V,E)$ be a directed graph with $|V|=n$ vertices. We define the layered graph $\mathrm{lay}(G)$ on the vertex set $V':=V\times{0,1,...,n}$ with two types of edges:
- For all edges $(i,j)\in E$ and all $l\leq n-2$ add an edge from $(i,l)$ to $(j,l+1)$ in $\mathrm{lay}(G)$,
- for all $i \in V$ and all $l\leq n-1$ add an edge from $(i,l)$ to $(i,n)$ in $\mathrm{lay}(G)$.
It is easy to see that the paths in the first $n$ layers of $\mathrm{lay}(G)$ directly correspond to paths of length less than $n$ in $G$. The last layer in $\mathrm{lay}(G)$ just serves as a catch basin for all paths of different lengths. Let us now prove the above theorem.
Proof of theorem 1.4. Let $\braket{G,s,t,1^k}$ be a given input graph instance with $|V(G)|=n$ nodes. Without loss of generality assume that $k\leq p(n)$ for some fixed polynomial $p:\mathbb{N}\rightarrow\mathbb{N}$. We first construct $\mathrm{lay}(G)$. Note that this is possible in $\mathsf{AC}^0$. We consider the counting Laplacian $L$ of $\mathrm{lay}(G)$ and run Ta-Shma's spectrum approximation algorithm (compare Theorem 5.2 in [Ta-13]) to approximate its singular values with error $\varepsilon=1/6$ and accuracy $\delta = 1/(2n\cdot k)$. If we obtain a singular value smaller than $\delta$, then we have with probability at least $5/6$,
which implies $\max_{i,j \in V(G)} N(i,j) \geq \max_{i,j\in V(\mathrm{lay}(G))} N(i,j) > k$. In this case we reject the input. Otherwise, if we do not obtain a singular value smaller than $\delta$, then we know with the same probability that the counting Laplacian of $\mathrm{lay}(G)$ is poly-conditioned. Thus, we can proceed as in theorem 1.1 and run Ta-Shma's matrix inversion algorithm to determine all entries of $L^{-1}$ with total error $\varepsilon'=1/6$ and accuracy $1/3$. For all $i\in V(G)$ we check in this way whether $L^{-1}((i,0),(i,n)) \geq 2$. If this is the case for some $i\in V(G)$, then there is a cycle in $G$ containing $i$, i.e. $N(i,i)=\infty$ in $G$, and we reject the input. Otherwise, we further check whether all entries of $L^{-1}$ are upper bounded by $k$ and if $L^{-1}((s,0),(t,n)) \geq 1$. The former implies $N(i,j)\leq k$ for all $i,j\in V(G)$, and the latter implies $N(s,t)\geq 1$ in $G.$ If both conditions are satisfied, we accept the input. Otherwise, we reject it. The total error probability of the algorithm is no higher than $\varepsilon + \varepsilon' = 1/3$. ☐
4. Counting few paths in quantum logspace
In this section we show how to push the algorithmic idea behind theorem 1.1 to obtain theorem 1.2, which shows how to count $st$-paths on graphs with a polynomial bound on the number of paths leaving $s$, and on the number of paths arriving in $t$, in $\mathsf{BQSPACE}(O(\log n))$. For this, we need the notion of an effective pseudoinverse, which we introduce in section 4.1. The proof of theorem 1.2 is in section 4.2.
4.1 Effective pseudoinverse
A close look at Ta-Shma's matrix inversion algorithm shows that it can be easily altered to also handle ill-conditioned matrices as input and only invert them on their well-conditioned part. In order to appropriately state this observation we make the following definition.
Definition 4.1 Effective pseudoinverse. Let $M$ be an $n\times n$ matrix with singular value decomposition $M=\sum_{j=1}^n \sigma_j \ket{u_j} \bra{v_j}$. For $\zeta>0$ we define the $\zeta$-effective pseudoinverse of $M$ as the matrix
Note that in the definition we essentially drop the largest terms of the actual inverse $M^{-1}=\sum_{j=1}^n \sigma_j^{-1} \ket{v_j} \bra{u_j}$. While this produces significant error to approximate $M^{-1}$ as a whole, we find that it can still give a good approximation for some relevant entries. We now state the refined version of Ta-Shma's matrix inversion algorithm which allows us to compute effective pseudoinverses of general matrices.
Theorem 4.2. Fix $\varepsilon(n), \zeta(n), \delta(n) > 0$ and $Z(n) \geq 1$. Let $M$ be an $n \times n$ matrix such that $Z \geq \sigma_1(M) \geq \cdots \geq \sigma_n(M)$. There is an algorithm running in $\mathsf{BQSPACE}(O(\log \frac{nZ}{\epsilon\delta}))$ that given $M$ and two indices $s,t\in [n]$ outputs an $\varepsilon$-additive approximation of the entry $M_{\widetilde{\zeta}}^+(s,t)$, where $\widetilde{\zeta}$ is a random value that is fixed at the beginning of the computation and is $\delta$-close to $\zeta$.
While it is a simple modification of [Ta-13], for completeness we provide a proof of this theorem in the appendix. The fact that we cannot control the exact threshold $\zeta$ of which singular values should be ignored during the effective pseudoinversion is a consequence of the ambiguity of quantum phase estimation, yet its uncertainty is limited by using Ta-Shma's consistent phase estimation procedure.
4.2 Proof of theorem 1.2
We now have the necessary tools to prove our final result which we recall here:
Theorem 1.2. Fix a polynomial $p: \mathbb{N} \rightarrow \mathbb{N}$. Let $G$ be a directed graph with $|V(G)|=n$ nodes such that
- $\forall j \in V(G) : N(s,j) \leq p(n)$ and $N(j,t) \leq p(n)$.
The idea for the proof is to approximate the effective pseudoinverse entry of the counting Laplacian $L_{\tilde{\zeta}}^+(s,t)$ for some small enough $\tilde{\zeta} = 1/\mathop{\rm poly}(n)$ instead of the actual inverse entry $L^{-1}(s,t)$. While ignoring the smallest singular values during the effective pseudoinversion normally leaves out the largest terms, we find that our path bounds imply low overlap of $\braket{s|v_j}$ and $\braket{u_j|t}$ for small singular values $\sigma_j$ such that entry $L^+_{\tilde{\zeta}}(s,t)$ is close to $L^{-1}(s,t)$.
Proof: We again consider the counting Laplacian and its singular value decomposition $L=I-A = \sum_{j=1}^n \sigma_j \ket{u_j}\bra{v_j}$. Its inverse is $L^{-1} = \sum_{j=1}^n \sigma_j^{-1} \ket{v_j}\bra{u_j}$. Now consider the vectors $(L^{-1})^T \ket{s}$ and $L^{-1}\ket{t}$. They contain as entries the number of paths starting in $s$ and the number of paths ending in $t$, respectively. Hence, we find for their squared $l_2$-norms:
where the last equalities of both lines follow because the $\{\ket{u_j}\}_{j\in[n]}$ and $\{\ket{v_j}\}_{j\in[n]}$ are orthonormal bases. As a consequence we obtain for each $j \in [n]$
Combining the two we find as a bound for the $j$-th term of the singular value decomposition of $L^{-1}$,
This allows us to estimate the error for computing an effective pseudoinverse entry $L_{\widetilde{\zeta}}^+(s,t)=\sum_{\sigma_j \geq \widetilde{\zeta}} \sigma_j^{-1} \left|\braket{s|v_j} \braket{u_j|t}\right|$ instead of the actual inverse entry $L^{-1}(s,t) = N(s,t)$. In fact, for $\widetilde{\zeta}\leq1/(5n^2\cdot p(n)^2)$ we have
Choosing $Z=n$, $\varepsilon=1/5$ and $\delta = \zeta = 1/(10n^2\cdot p(n)^2)$ in theorem 4.2 ensures $\widetilde{\zeta} \leq 1/(5n^2 \cdot p(n)^2)$ and yields an additive $2/5$ approximation of $L^{-1}(s,t)$ within the desired space complexity. Rounding to the closest integer gives the number of paths from $s$ to $t$. ☐
A natural open question is whether the simultaneous polynomial bound on (i) the number of paths starting from $s$ and on (ii) the number of paths ending in $t$ is really necessary for a $\mathsf{BQSPACE}(O(\log n))$ procedure. Unfortunately, at least with our approach above, this seems to be the case. Note that (i) implies low overlap of $\ket{s}$ with the left singular vectors $\ket{v_j}$ of $L^{-1}$ and (ii) implies low overlap of $\ket{t}$ with the right singular vectors $\ket{u_j}$ of $L^{-1}$. It turns out that if only one of the two is small, then the contribution of $\sigma_j^{-1} \braket{s|v_j} \braket{u_j|t}$ to $L^{-1}(s,t)$ can still be significant for very small $\sigma_j$ but will be ignored in the pseudoinversion.
Acknowledgements
We thank François Le Gall for discussions about the differences between language and promise classes. He made us aware that our results can be seen as first evidence that the language classes $\mathsf{BQL}$ and $\mathsf{BPL}$ are distinct. We further acknowledge useful discussions with Klaus-Jörn Lange and we thank Lior Eldar, Troy Lee and Ronald de Wolf for valuable comments on an earlier draft. RE was supported by the Program QuanTEdu-France (ANR-22-CMAS-0001). SA was partially supported by French projects EPIQ (ANR-22-PETQ-0007), QUDATA (ANR18-CE47-0010), QUOPS (ANR-22-CE47-0003-01) and HQI (ANR-22-PNCQ-0002), and EU project QOPT (QuantERA ERA-NET Cofund 2022-25).
References
[AB06] S. Arora and B. Barak. Computational Complexity: A Modern Approach. Cambridge University Press, 2006.
[AKL+79] Romas Aleliunas, Richard M. Karp, Richard J. Lipton, László Lovász, and Charles Rackoff. Random walks, universal traversal sequences, and the complexity of maze problems. In 20th Annual Symposium on Foundations of Computer Science, pages 218--223, 1979.
[AL98] Eric Allender and Klaus-Jörn Lange. RUSPACE($\log n$) $\subseteq$ DSPACE($\log^2 n/\log \log n$). Theory of Computing Systems, 31, 1998.
[All23] Eric Allender. Guest column: Parting thoughts and parting shots. SIGACT News, 54(1):63–81, 2023.
[BJLR91] Gerhard Buntrock, Birgit Jenner, Klaus-Jörn Lange, and Peter Rossmanith. Unambiguity and fewness for logarithmic space. In Fundamentals of Computation Theory, pages 168--179. Springer, 1991.
[Coo85] Stephen A. Cook. A taxonomy of problems with fast parallel algorithms. Information and Control, 64(1):2--22, 1985.
[DSTS17] Dean Doron, Amir Sarid, and Amnon Ta-Shma. On approximating the eigenvalues of stochastic matrices in probabilistic logspace. Computational Complexity, 26:393--420, 2017.
[FL18] Bill Fefferman and Cedric Yen-Yu Lin. A complete characterization of unitary quantum space. In 9th Innovations in Theoretical Computer Science Conference, volume 94 of Leibniz International Proceedings in Informatics, pages 4:1--4:21, 2018.
[FR21] Bill Fefferman and Zachary Remscrim. Eliminating intermediate measurements in space-bounded quantum computation. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, 2021.
[GLW23] François Le Gall, Yupan Liu, and Qisheng Wang. Space-bounded quantum state testing via space-efficient quantum singular value transformation. arXiv preprint arXiv:2308.05079, 2023.
[GR22] Uma Girish and Ran Raz. Eliminating intermediate measurements using pseudorandom generators. In 13th Innovations in Theoretical Computer Science Conference, volume 215, pages 76:1--76:18, 2022.
[GRZ21] Uma Girish, Ran Raz, and Wei Zhan. Quantum logspace algorithm for powering matrices with bounded norm. In 48th International Colloquium on Automata, Languages, and Programming, volume 198, pages 73:1--73:20, 2021.
[GSTV11] Brady Garvin, Derrick Stolee, Raghunath Tewari, and N. V. Vinodchandran. ReachFewL = ReachUL. In Computing and Combinatorics, pages 252--258. Springer, 2011.
[HHL09] Aram W. Harrow, Avinatan Hassidim, and Seth Lloyd. Quantum algorithm for linear systems of equations. Physical Review Letters, 103(15), 2009.
[kannan2008stcon] Sampath Kannan, Sanjeev Khanna, and Sudeepa Roy. STCON in directed unique-path graphs. In IARCS Annual Conference on Foundations of Software Technology and Theoretical Computer Science, 2008.
[Lan97] Klaus-Jörn Lange. An unambiguous class possessing a complete set. In STACS 97, pages 339--350. Springer, 1997.
[LPW08] D.A. Levin, Y. Peres, and E.L. Wilmer. Markov Chains and Mixing Times. American Mathematical Society, 2008.
[MW12] Dieter van Melkebeek and Thomas Watson. Time-space efficient simulations of quantum computations. Theory of Computing, 8(1):1--51, 2012.
[Rei08] Omer Reingold. Undirected connectivity in log-space. Journal of the ACM, 55(4):1--24, 2008.
[Sav70] Walter J. Savitch. Relationships between nondeterministic and deterministic tape complexities. Journal of Computer and System Sciences, 4(2):177--192, 1970.
[SZ99] Michael Saks and Shiyu Zhou. $\mathrm{BP}_\mathrm{H}\mathrm{SPACE}(S) \subseteq \mathrm{DSPACE}(S^{3/2})$. Journal of computer and system sciences, 58(2):376--403, 1999.
[TS13] Amnon Ta-Shma. Inverting well conditioned matrices in quantum logspace. In Proceedings of the 45th Annual ACM Symposium on Theory of Computing, page 881–890, 2013.
Appendix: Effective pseudoinversion in quantum logspace
The algorithm for the effective pseudoinversion is essentially identical to Ta-Shma's matrix inversion procedure except for a small change in the rotation step to appropriately treat ill-conditioned matrices. For completeness we describe it here but refer to [Ta-13] for the detailed complexity and error analysis.
Proof sketch of theorem 4.2. We make the following two simplifying assumptions:
- Without loss of generality we assume that $Z=1$. Otherwise, we simply choose $Z = n\cdot |M|_{\max}$ as an upper bound for $\sigma_1(M)$ and rescale the matrix with factor $1/Z$. Approximating the entries of a $\tilde{\big(\frac{\zeta}{Z}\big)}$-effective pseudoinverse of this rescaled matrix up to accuracy $\varepsilon \cdot Z$ gives an $\varepsilon$ approximation of the entries of a $\tilde{\zeta}$-effective pseudoinverse of $M$ within the same space complexity.
- Furthermore, we assume the matrix $M$ to be Hermitian. Otherwise we use the well-known reduction to the Hermitian case
It is easily verified that the eigenpairs of $H$ are given by
such that
Now, let the spectral decomposition of the matrix be given by $M=H=\sum_{j=1}^n \lambda_j \ket{h_j}\bra{h_j}$ and let $\ket{t} = \sum_{j=1}^n \beta_j \ket{h_j}$. The algorithm works on four registers: An input register $I$, an estimation register $E$, a shift register $S$ and an ancillary register $A$ of dimension at least three.
1. We start by preparing the initial state
2. We then apply the consistent phase estimation procedure (compare Section 5.2 in [Ta-13]) to the input, estimation and shift register and obtain a state close to
where $s(j)$ is the j-th section number, that is a fixed classical value depending on $h_j$ only, from which we can recover a $\delta$-approximation $\widetilde{\lambda}_j = \widetilde{\lambda}(s(j))$ of the eigenvalue $\lambda_j$.
3. We next approximately apply a unitary map acting on the shift and ancillary register partially described by
4. We reverse the consistent phase estimation and are left with a state close to
Note that the approximations of the eigenvalues are monotone in the sense that $\lambda_i \leq \lambda_j$ implies $\widetilde{\lambda}_i \leq \widetilde{\lambda}_j$. From this we get the existence of $\widetilde{\zeta}_+ > 0$ and $\widetilde{\zeta}_- < 0$, both in absolute value $\delta$-close to $\zeta$, such that
Choosing and combining symmetric shifts for the positive and negative eigenvalues during the consistent phase estimation allows to assume $|\widetilde{\zeta}_+| = |\widetilde{\zeta}_-|$. Denoting this value by $\tilde{\zeta}$ we find
5. Finally, we measure the ancillary register. If the measurement outcome is $\ket{\text{well}}_A$, this leaves us with a state close to the normalized desired one
In fact, estimating the success-probability of this measurement outcome gives a good approximation of
from which we recover $\Big|M_{\widetilde{\zeta}}^+\ket{t}\Big|_2$.
Repeating the steps above sufficiently many times lets us create multiple copies of the desired state, assuming $\Big|M_{\widetilde{\zeta}}^+\ket{t}\Big|_2$ is non-negligible. We then use Ta-Shma's space-efficient tomography procedure Theorem 6.1 in [Ta-13] to approximately learn the state, and in particular entry
☐
This document is in arXiv: 2408.12473.